Двухсерверная конфигурация Эра: плюсы, минусы и реальная отказоустойчивость
- Иллюзия простоты
- Зачем выбирают двухсерверную конфигурацию?
- Критерии достаточности одного сервера
- Математика надежности
- Failover-переключение в архитектуре Active-Active
- Судьба активных разговоров во время Failover-переключения
- Проблема сети и таймауты
- Режим вывода сервера из эксплуатации (Deservice)
- SIP-телефоны и софтфоны
- Клиентские приложения
- Провайдеры и внешние АТС
- IVR и медиа
- Базы данных
- Особенности файловой системы
- Интеграции
- Сплит-брейн (Разделение на острова)
- Плюсы и минусы двухсерверной конфигурации
- Идеальный HA-контур
- Альтернативный подход: Active-Passive с гео-распределением
Иллюзия простоты

Когда система работает на одном сервере, мы не задумываемся о внутренних процессах. Нас не волнуют зацепленные связи между компонентами, потоки данных или нагрузка на каналы. Внутри одного узла нет явных сетевых задержек, нет проблем синхронизации времени, нет резервных точек подключения. Понятие «точка целостности» даже не возникает, пока мы находимся в границах единичного. Нам не нужно заботиться о проблемах сплит-брейна, кворума или механизмах восстановления данных.
Это большое благо односерверной архитектуры. Но это благо исчезает сразу, как только система выходит за пределы одного узла.

В статье мы рассмотрим особенности двухсерверной конфигурации. Это первый шаг за пределы одиночного сервера. Но уже на этом шаге нас ждет весь спектр последствий выбора пути в многосерверную конфигурацию.
Очевидно, что дополнительные серверы позволяют распределять нагрузку. Однако аспект масштабирования мы оставим за скобками — он менее интересен в контексте рисков. Нас интересует резервирование. В этом аспекте скрыт огромный пласт деталей, невидимых при поверхностном взгляде, но напрямую влияющих на результат.
В основном мы посвятим внимание конфигурации Active-Active — два сервера в рамках одного экземпляра системы.
Зачем выбирают двухсерверную конфигурацию?
Двухсерверную конфигурацию выбирают, как правило, ради отказоустойчивости. А зачем? Запрос на отказоустойчивость — это результат отработки рисков проекта. Очевидный риск — выход одного сервера из строя.
Однако отказоустойчивость — это не обязательно несколько серверов. Если сервер категории High Availability (аппаратно надежный), риск его физического выхода из строя часто закрыт на более низком уровне. В таких случаях выгода от двухсерверной конфигурации может не перевешивать объем усилий и усложнений, которые она влечет.

|
Важно понимать: отказоустойчивость платформы не влечет напрямую отказоустойчивость всей системы. Платформа «Эра» — лишь подсистема. В общую систему включены телефоны, софтфоны, клиентские приложения, провайдеры связи, базы данных, брокеры, файловые хранилища и интегрированные системы. Все они разделены сетью, имеют собственные адреса и механизмы подключения. Требования по отказоустойчивости предъявляются к большой суперсистеме в целом, а не только к платформе. |
Критерии достаточности одного сервера
Прежде чем переходить к сложностям, давайте честно ответим на вопрос: когда одного сервера достаточно? Платформа «Эра» позволяет построить отказоустойчивую схему, но она не является «волшебной таблеткой». Если инфраструктура вокруг не готова, второй сервер лишь усложнит жизнь.
Односерверная конфигурация оправдана, если:
-
Требования к доступности ниже 99%. Бизнес может позволить себе перерывы связи на время восстановления железа.
-
Используется аппаратно надежный сервер. Сам сервер категории High Availability (резервные блоки питания, RAID-массивы, ECC память) уже закрывает значительную часть рисков отказа железа. Тем более виртуальные вычислительные мощности.
-
Обрыв текущих разговоров некритичен. Потеря текущих разговоров в момент сбоя сервера не более критична, чем возникновение вынужденного перерыва сервиса.
-
Ограниченный бюджет. Нет ресурсов на поддержку двойной инфраструктуры.
-
Инфраструктура имеет единые точки отказа (SPOF или single point of failure). Если серверы питаются от одного ИБП, выходят в сеть через один коммутатор, другие очевидные точки отказа — второй сервер не спасет от аварии инфраструктуры.
-
В инфраструктуре не выделены специализированные HA-сервисы - файловые хранилища, базы данных.
-
Отсутствие круглосуточной поддержки. Нет админа 24/7, который сможет отреагировать на инциденты, которые всё же случаются в сложных схемах.
-
Не проведена оценка рисков. Нет карты рисков бизнеса, чтобы исследовать зависимости и обосновать затраты на резервирование.
|
Если эти пункты проявляют себя — не усложняйте. Надежный одиночный сервер определенно лучше, чем плохо настроенный кластер. По меньшей мере стоит еще раз внимательно взвесить, действительно ли выдвижение в многосерверную систему обосновано утвержденными требованиями и риски действительно устраняются. |
Математика надежности
Предположим, мы добавили второй сервер. Рассмотрим модель расчета надежности. Пусть надежность одного сервера — R. В системе из двух независимых параллельных серверов система функционирует, пока работает хотя бы один узел. Надежность такой системы вычисляется по формуле:
R_sys = 1 - (1 - R)² (0.9999 против 0.99)Если надежность сервера 0.99, то надежность системы из двух серверов возрастает до 0.9999. Однако вероятность того, что хотя бы один сервер выйдет из строя, увеличивается, так как компонентов стало больше:
P_failure = 1 - R² (0.0199 против 0.01)|
Вывод: Добавление сервера повышает общую доступность системы, но увеличивает частоту событий отказа компонентов, которые нужно мониторить и обслуживать. |
Failover-переключение в архитектуре Active-Active

Итак, второй сервер добавлен. Для полноценной работы состав ролей на серверах должен быть идентичным и полнофункциональным. Микросервисы распределились, появились пары и группы, определены лидеры в парах с точками целостности. Массовые процессы (обслуживание вызовов) статистически распределяются по обоим узлам. Часть активных микросервисов на первом сервере, часть активных на втором сервере. При должной настройке оба узла нагружаются равномерно.
Вдруг срабатывает риск — теряется один сервер.

Группы микросервисов, отвечающие за точку целостности, имеют по одному активному экземпляру (грубо, поскольку есть механизмы тонкой настройки разделения точки целостности по доменам, классам и другим критериям). Потеря доступа к ним приводит к пропаданию доступности. Платформа «Эра» детектирует это почти сразу (2 секунды). Доступность — атрибут качества второго приоритета, главнейший драйвер архитектуры наряду с масштабируемостью.

Происходит скорая failover-активация резервных экземпляров. Двухсерверное распределение активных микросервисов переходит в односерверное. Через короткое время (5-10 секунд) новый поступивший запрос будет обработан. Администратору не придется участвовать в срочном восстановлении сервиса вручную.

Судьба активных разговоров во время Failover-переключения
Но давайте зададим важный вопрос, который волнует руководителя:
— А что происходит с теми разговорами, которые уже идут в момент аварии?
Здесь нам придется снять розовые очки. Чудес не бывает: частичное зацепление сессий при отказе узла неизбежно. Сценарии развития событий будут разными:

-
Только некоторым абонентам повезет остаться в полном объеме сервиса без каких-либо изменений. Таких в среднем 12%.
-
Другая часть абонентов останется с голосом, но без возможности управления сигнализацией: вы не сможете поставить звонок на удержание или перевести его. Таких в среднем 44%.
-
Оставшаяся часть окажется в тишине и без возможности управления: такие разговоры на этом этапе стоит считать потерянными. Таких в среднем также около 44%.
Почему так происходит? В двухсерверной конфигурации микросервисы распределены примерно 50 на 50. Около половины текущих разговоров действительно не оборвутся в моменте. Это те случаи, когда медиашлюз, обрабатывающий поток голоса, остался на живом сервере, либо все сервисы сигнализации остались на живом сервере, сумев при необходимости локализовать медиаобработку.
Однако для другой половины ситуация сложнее. Чтобы разговор выжил полностью, необходимо, чтобы все микросервисы, обслуживающие конкретный вызов (фасады, логика, медиа), одновременно оказались на оставшемся узле. Вероятность такого совпадения в динамической среде невелика - всего около 12%. Поэтому 44% разговоров окажутся без медиа и с разрывом в цепочке сигнализации. Можно считать, что они на этом этапе потерялись.
Сервис восстановления разговоров
Существует ли решение? Да. В платформе «Эра» есть специальный Сервис восстановления разговоров.
Как он работает? При потере сервера система адаптирует failover-конфигурацию, подхватывает или дожидается необходимых регистраций и инициирует восстановление плеч зацепленных потерей вызовов.
На всю эту цепочку выделяется до 20 секунд. Сервис способен восстановить все разговоры почти наверное (термин теории вероятностей), вернув абонентам и голос, и управление. Почти — потому что некоторые отдельные разговоры могут всё же порваться, если в интервале попытаются воспользоваться удержанием или осуществить перевод. Кстати, только такой механизм способен восстановить вызов в IVR-сценарий, если микросервис IVR остался на недоступном сервере.

И здесь мы видим яркое проявление архитектурного предела двухсерверной схемы. Если мы сравним её с конфигурацией из 4-х и более серверов, где роли жестко разделены (отдельные узлы только под медиа, отдельные — под сигнализацию), картина меняется радикально. В такой архитектуре даже без сложного сервиса восстановления разговоров потеря одного сервера не приводит к обрыву голоса. В худшем сценарии (теряется именно один из серверов сигнализации, вероятность этого не более 50%) лишь половина вызовов останется с голосом без возможности управления, остальные случаи и разговоры — с сохранением управления.
|
Вывод прост: два сервера дают отличную отказоустойчивость для новых вызовов и быструю реакцию системы, но для бесшовного сохранения текущих разговоров требуются либо сервис восстановления разговоров, либо переход на многосерверную архитектуру с разделением ролей. |
Проблема сети и таймауты
Но бывает, что теряется не сервер, а пропадает сеть до него или между ними. TCP-подключения могут «зависать» до 60 секунд, если удаленный узел перестал отвечать, но не разорвал соединение. Failover не произойдет, пока подключение не разорвется.
Для оперативной активации система рассылает внутри heartbeats (сигналы жизни). Отсутствие heartbeat влечет принудительный разрыв TCP-соединений. Здесь мы входим в зону принятия решения. Серверу непонятно: сеть восстановится через секунду или потеряна навсегда?
Существуют ошибки двух родов:
-
Ошибка 1 рода (Ложная тревога): Не ждать восстановления канала, когда он восстановится через несколько секунд.
Последствия: Кратное перетекание активности, частичные перезагрузки, высокая утилизация CPU, риск сплит-брейна. Часть процессов реального времени обрывается, упершись запросами в потерянный сервер и разорванное соединение.
-
Ошибка 2 рода (Пропуск аварии): Ждать восстановления долго, когда канал потерян реально.
Последствия: Подмирание системы на время таймаута (вплоть до 60 секунд TIME_WAIT). Часть текущих процессов обрывается по таймауту (в SIP — 32 сек, в данных — от 5 до 60 сек).

Выбор стратегии должен опираться на статистику сбоев сети:
-
Если сеть иногда «мигает» на 3–10 секунд и восстанавливается без разрыва — оптимальнее принять Ошибку 2 рода (подождать 10–15 секунд), чтобы избежать лишней миграции.
-
Если пропадание сети неразличимо с падением сервера (всякий раз более минуты) — стоит принимать Ошибку 1 рода (реагировать быстро).
Это управляется конфигурационной опцией интервала ожидания (pang_to_disconnect_sec). По умолчанию — 10 секунд. Идеальный вариант избежать обоих родов ошибок — исключить подмирающие сети на уровне инфраструктуры (например, подключив серверы к одному отказоустойчивому коммутатору). Тогда можно разрывать подключения сразу, установив опцию в 0. Если нет — нужно делать обоснованный выбор и принимать последствия.
Очевидно, чем дольше здесь ожидание, тем меньше шансов на восстановление зацепленных разговоров в отведенные для этого 20 секунд.
Режим вывода сервера из эксплуатации (Deservice)

«Эра» имеет инструменты плавного вывода сервера из эксплуатации. Администратор мастер-домена переключает подготовленные пресеты активности серверов. Если сервер деактивирован в пресете, он не отключается моментально, а в течение пары часов перестает принимать новую работу. Микросервисы перестают участвовать в выборах, но дообслуживают текущие контексты. Активные экземпляры постепенно один за другим передают нагрузку на оставшийся сервер. Фасадные микросервисы отказывают или перенаправляют входящие подключения.
Через два часа (предельное время телефонного разговора) сервер можно выключать безопасно. Это один из бонусов многосерверной конфигурации.
В роадмапе на начало 2026 года есть развитие функционала для колл-центров. На этот момент переезд некоторых микросервисов колл-центра может повлечь потерю отслеживания текущих вызовов. Мы работаем над этим, особенно учитывая, что продуктовый слой колл-центра опирается на инвокейшены в распределенной БД и не зависит от перезапусков сервисов.
SIP-телефоны и софтфоны
Если устройство подключено к живому серверу — потеря второго узла для него незаметна. Если устройство было подключено через упавший сервер — ему нужно переподключиться. Простое добавление второго сервера само по себе этого не обеспечивает.
Варианты решения:
-
Резервный outbound proxy. В настройках устройства указываются альтернативные точки подключения.
-
WebSocket: Устройство чувствует потерю и пробует альтернативный узел (так работает веб-софтфон). Список адресов задается в самом софтфоне или в приложении администратора платформы, если софтфон запускается автоматически.
-
UDP: Устройство попытается отправить запрос на живой адрес при следующей перерегистрации. Интервал должен быть достаточно коротким (например, 180 сек), либо сервер должен отправить NOTIFY с командой перерегистрации, что можно включить в конфигурации (параметр SG reregister), но поддерживается далеко не всеми устройствами.
-
TCP: Работает в этой части аналогично UDP, но в большинстве случаев имеет зависимость от зависания соединения. Телефоны просто ждут таймаута прежде чем пытаться переподключиться.
-
-
Simultaneous Registration (RFC-5626). Параллельная регистрация на несколько узлов (например, телефоны Avaya). Сервер сможет вызвать устройство по резервному маршруту сразу.
-
Virtual IP. Виртуальный адрес в подсети устройств, привязанный к дополнительным экземплярам SG на обоих серверах. Активен только тот экземпляр, на сервере которого обнаружен VIP. Автоматика управляет активацией адреса с помощью адаптированных в проекте шелл-скриптов. Телефон всегда видит один адрес. Если SG слушают только VIP (не слушает основной локальный адрес), перерегистрация не требуется, так как все пути до устройства сохраняют валидность.
-
Две учетные записи. Вторая учетка с переадресацией при отсутствии регистрации. Телефон зарегистрирован дважды - под разными учетными записями. Преимущественно используется первая зарегистрированная учетка. Минусы этого подхода:
-
двойная утилизация лицензий на учетные записи
-
при потере сервера восстановление активного разговора невозможно
-
|
Вывод: Для полноценного резервирования устройств недостаточно просто добавить второй сервер. Нужна настройка, адаптированная под возможности подключаемых устройств. Настройка сервера, устройства или того и другого. |
Клиентские приложения
Рассматриваем два кейса:
-
В момент подключения пользователя один из серверов уже недоступен.
-
Часть пользователей подключена к веб-серверу на внезапно ставшем недоступном сервере.
Идеально, если от пользователей не требуется никаких дополнительных действий, чтобы привычные действия в любых условиях приводили к целевому результату.
Какие есть варианты:
-
Virtual IP. Приложение пользователя теряет доступ и восстанавливает его без изменения адреса. Это дополнительные веб-серверы.
-
Назначение управляется извне. Ответственность за скорость на внешнем контроллере (keepalived, pacemaker).
-
Назначение управляется изнутри. При двух серверах для принятия решения о назначении VIP требуется тонкая настройка кворума.
-
-
Внешний балансировщик. Важно чтобы он был HA, иначе это SPOF. Оправдан, если клиенты не умеют работать со списком адресов, или нужно скрывать внутреннюю структуру. Если клиенты умеют работать с несколькими адресами, это надежнее и проще.
-
Пользователь сам выбирает. В строку ссылок браузера заносит обе точки подключения. Переключается вручную при недоступности. Вариант далек от идеала – дополнительне действия налицо.
-
Скрипт connector.html. Является частичной автоматизацией предыдущего варианта. Осуществляет пробные подключения ко всем серверам и перенаправляет на гарантированно живой сервер. Прозрачно для пользователя.
-
Множественное DNS имя. Может являться частью решения. Например, DNS может обновляться на основе health-check мониторинга серверов (ожидается, что TTL должен быть коротким).Либо с опорой на round-robin и несколько попыток F5 или автоматизированного websocket подключения.
Если клиентское приложение раз подключилось, то при должной настройке его переподключение к живому серверу при потере связи с текущим сервером происходит автоматически. (Сейчас с опорой на virtual ip или multi dns с полной перезагрузкой клиентского приложения.)
|
Вывод: Для полноценного резервирования пользовательских подключений недостаточно просто добавить второй сервер. Нужна проработка подходящего сценария переключения в применении к конкретному проекту. |
Провайдеры и внешние АТС
Потеря сервера не должна приводить к потере связи с ТФОП (PSTN). Без этого очевидно невозможно обеспечить полнофункциональную доступность. Варианты организации резервной схемы:
-
Регистрация. При должных настройках учетные записи провайдеров оперативно зарегистрируются с другого экземпляра ESG на оставшемся доступном сервере. Это вариант по умолчанию.
-
Simultaneous Registration (RFC-5626). Если внешняя система поддерживает, можно резервировать также фасад внешней системы через разные edge-proxy. Не будет и перерыва в маршрутизации на такую учетную запись провайдера.
-
Провайдеры без регистрации. Поведение по умолчанию такое же, как для провайдеров с регистрацией - ответственность за обслуживание будет перетекать на доступный сервер. Либо учетная запись может обслуживаться одновременно на нескольких экземплярах ESG, это требует настройки. В любом случае внешняя система должна уметь распределять вызовы по доступным узлам «Эры». Если один узел не отвечает, отправлять на другой. То есть это требует настройки внешнего узла.
-
Virtual IP. Если внешняя система не поддерживает несколько адресов для учетной записи P2P (без регистрации), используем VIP на экземплярах ESG. Активен тот экземпляр, на сервере у которого обнаруживается VIP.
-
Альтернативные учетные записи. Для исходящих вызовов работает через правила маршрутизации: если одна учетка недоступна, вызов уходит на следующее по приоритету подходящее по фильтрам правило маршрутизации, указывающее на альтернативную учетную запись провайдера (обслуживается на другом сервере).
|
Вывод: Нужно внимательно оценить возможности внешних систем и выбрать и настроить подходящие варианты резервирования для каждого внешнего узла. Если в нашей системе много доменов, то имеет смысл подготовить конфигурацию и мастер-домен к различным вариантам возможных настроек учетных записей. |
IVR и медиа
В версиях двухлетней давности потеря сервера с IVR или медиашлюзом, обслуживающим его медиа-сеанс, влекла потерю вызова.
-
Сейчас потеря сервера с медиашлюзом влечет создание нового медиа-сеанса на доступном узле и автоматический перезапуск текущего компонента сценария (медиа-компонента).
-
Потеря сервера с IVR (при включенном режиме восстановления разговоров) запускает сценарий с последней сохраненной точки.
|
Вывод: Сохранение IVR сессий в общем случае требует активации сервиса восстановления разговоров и глубокой переработки сценариев IVR, учитывающей возможность обрыва на любом компоненте любого сценария. |
Базы данных
Система хранит доменное дерево и учетные записи в PostgreSQL. Архивы могут быть здесь же (в том числе и в другом инстансе PostgreSQL) или вынесены в ClickHouse. Сервер БД также должен быть зарезервирован, иначе это профанация отказоустойчивости.
При настройке «Эры» задаются строки подключения. «Эра» выбирает подключение к мастеру. Если мастера нет в моменте, но есть read-only рекавери, загрузка может пройти и с рекавери-инстанса с целью снижения времени недоступности.
|
Мы глубоко убеждены: коммуникационную систему реального времени в схемах с резервированием следует держать отдельно от БД. Это разделение ответственности и независимое администрирование. |
Одна строка подключения, если фасадный балансировщик HA. Или несколько строк подключения, если как-то иначе. Вплоть до того, что для разных серверов можно задать разные наборы строк подключения.
Вариант «БД внутри контура»
Часто встречается дефолтная установка: БД рядом с платформой, на этой же паре серверов (потоковая репликация). Если нет внешних инструментов, используется встроенный контроллер репликации (микросервис middleware).
-
Задача: следить за подключениями и при потере мастера (через 30 сек) активировать рекавери.
-
Риск: При возобновлении связи возникает сплит-брейн (два мастера). Контроллер делает из бывшего мастера новую реплику с нуля. Это может длиться часами. В это время система без актуальной реплики.
-
Поэтому контроллер тянет время перед переключением. Лучше подождать минуту, чем остаться без репликации на часы.
Встроенный контроллер не заменяет профессиональные инструменты (Patroni и т.д.). Он закрывает кейсы минимально достаточным образом. Управлять его поведением можно только условным тумблером Вкл-Выкл.
Рекомендация: В проектах с серьезными требованиями выносите БД из контура коммуникационной подсистемы.
Брокер для коллекций исторического типа
Для гарантированного сохранения архивных данных может использоваться брокер. Это относится к случаю, когда архивы также хранятся в БД PostgreSql. С версии 1.10 появилась возможность переключать коллекции исторического типа с хранилищем в PostgreSQL в режим работы через брокера (используются Mnesia или KAFKA).
Если же система настроена на работу с ClickHouse, то брокер KAFKA используется априори. Однако стоит помнить, что несмотря на распределенную архитектуру и ClickHouse и KAFKA, двухсерверный вариант не является полноценным, поскольку не обеспечивает кворума при потере сервера, а значит подвержен split-brain. Таким образом, двухсерверная конфигурация платформы не должна сопровождаться развертыванием KAFKA и CLICKHOUSE на этих же двух серверах.
|
Итог по БД: Для полноценной схемы следует резервировать БД. Идеально, если БД существует и администрируется инфраструктурой отдельно как обособленная подсистема. |
Особенности файловой системы
В многосерверном режиме платформа работает с файловыми системами нескольких хостов. Файл, созданный на первом хосте, может потребоваться сценарию на втором. В односерверном режиме это не критично, в двухсерверном — требует решения.
Те кто настраивал работу с файлами в сценариях наверняка обратили внимание, что адресация файлов не абсолютная, а с помощью макро-путей, адресующих различные разделы и папки. Относительные пути одинаковые для всех серверов, а абсолютные могут различаться на разных серверах в соответствии с конфигурацией. Это не рекомендованный паттерн, но возможный вариант.
Разделы хранения:
-
Приватный раздел. Исполняемые файлы, логи, временные файлы. Независим для каждого сервера.
-
Каталог SYNC. Автоматическая реал-тайм синхронизация средствами платформы (медиафайлы, сценарии, сертификаты). Запись одним случайным сервером. Это хранилище для ограниченного количества файлов/каталогов (в пределах 100 тысяч). Этот каталог обширно используется самой системой, его настройкой администратору заниматься не предстоит. Важно лишь следить, чтобы он не захламлялся проектными данными.
-
Сетевые каталоги (SITESHARE, GLOBALSHARE). Для проектных артефактов длительного хранения и не слишком частого доступа лучше использовать их. Сюда может быть нацелено хранилище вложений модели данных. Требуют HA NFS-сервер за пределами платформы. Без настройки подключения к NFS - это просто локальные каталоги, и использовать их для многосерверных задач, в том числе для вложений, нецелесообразно.
-
S3 хранилище. Идеальный способ для записей разговоров и вложений. Предполагается, что S3-хранилище уже есть и зарезервировано в инфраструктуре или в облаке. В этом случае целесообразно настроить туда отправку записей разговоров и хранение там вложений модели данных. В отличие от NFS-папок подключается и настраивается в каждом домене отдельно.
-
Каталог записей (Локальный). Предполагается, что он подключен к NFS. Но если не настроены ни NFS, ни S3, каждая запись оказывается на диске одного сервера, но ищется на всех серверах. Резервирования в этом случае нет. Это дефолтный режим, приемлемый для односерверных конфигураций, и ограниченно приемлемый для двухсерверной - все записи доступны только в момент, когда доступны оба сервера, иначе доступна только их часть.
-
Локальный каталог вложений (микросервис fs). Хранит файлы локально, дублирует на своих серверах. Данные не синхронизируются автоматически между разными серверами. Режим применяется по умолчанию для вложений, приемлем для односерверного режима и ограниченно приемлем для двухсерверной конфигурации. Пропадание узлов может приводить к постепенной рассинхронизации файлов. Если вложения не заменяются, а работают только на первичное размещение (например почтовые письма), то даже спустя время после множества односерверных периодов будут доступны все вложения таких классов при активности обоих серверов.
То есть если не подключить внешнее хранилище с автоматическим обеспечением целостности, то по началу незаметная и неучтенная работа по синхронизации файловых хранилищ, перекладывается в будущее на админа, которому предстоит синхронизировать файлы после завершения работ по восстановлению сервера или связи. А записи разговоров рискуют быть потерянными вместе с сервером.
В настоящее время подключение внешнего файлового хранилища выглядит так:
-
сначала в домене создаются хранилища с информацией о подключении и специальными именами;
-
затем в домен накатывается продуктовый слой;
-
в течение нескольких часов или после перезапуска, модифицируются также встроенные коллекции коммуникационного слоя платформы.
Таким образом все классы автоматически привязываются к соответствующим файловым хранилищам для вложений. Изменить привязку к другому файловому хранилищу можно и вручную.
| Важно помнить, что при изменении хранилищ текущие файлы вложений не переносятся автоматически. |
Правила записи создаются или модифицируются на использование одного из этих хранилищ. Если разные правила записи указывают на различные доступные в домене хранилища, то поиск записи ведется в том хранилище, куда оно было сохранено. Код хранилища упомянут во внутренней ссылке.
|
Итог по файлам: Для качественной реализации отказоустойчивости следует подключать внешние хранилища: S3 или NFS. «Эра» — одна подсистема, файловое хранилище — другая подсистема HA-суперсистемы. |
Интеграции
Вопрос интеграций — открытое проектное поле. Обобщение по аналогии с предыдущими пунктами:
-
Узлы внешних систем также должны быть зарезервированы.
-
Доступ к ним либо через Virtual Ip (например файловые хранилища, балансировщики, SBC), либо через Multi DNS (например вебсервисы, мессенджеры) либо через несколько адресов (например siprec, транскрибация, брокеры, базы данных).
-
С учетом логики конкретной интеграции могут применяться альтернативные менее приоритетные маршруты и сценарии.
-
Если интегрируемая система сама подключается к «Эре», у нее должна быть способность переподключаться. Тут применим весь спектр вариантов, упомянутых в разделах про внешние устройства и клиентские приложения.
Сплит-брейн (Разделение на острова)
Если связь между серверами теряется, но оба сервера активны, возникает т.н. split-brain. Система адаптируется, активируя резервные экземпляры и, возможно, резервный инстанс БД. Возникают две параллельно работающие системы.
Если это возможно, то конфигурация должна быть настроена на кворум.
| Кворум — сохранение точки целостности лишь на острове из более чем половины доступных друг другу серверов. |
Острова без кворума выводятся из обслуживания (микросервисы тухнут, фасадные порты закрываются, сценарии и обращения к внешним сервисам прекращаются). Они переходят в режим ожидания появления кворума.
В двухсерверной системе возможно состояние «два острова по половине серверов». Применение обычного кворума выключит сервис на обоих островах. Необходимо оставить ровно один остров в работе.
«Эра» предоставляет два механизма:
-
Арбитр. Используется произвольный внешний сервер в сети. Наличие пинга до арбитра дает кворум половине серверов. Механизм работает, если серверы платформы в одной подсети, то есть пропадание связи означает по меньшей мере изоляцию недоступного сервера, то есть недоступность арбитра для него самого. Но если доступ к арбитру может остаться на обоих серверах при том, что канал между ними недоступен, то такой подход не решает проблему, а влечет ситуацию, когда кворум фактически не настроен. Для этого есть второй механизм…
-
Связь через внешний канал. Если арбитр может оказаться доступен обоим, значит по меньшей мере через арбитра эти серверы связаны через внешнюю сеть. Через эту же внешнюю сеть серверы могут обратиться друг к другу и провести выборы. Требуется настройка URL для обращения каждого сервера к каждому другому через внешнюю сеть. Во-первых настройку в конфигурации, а во-вторых настройку в маршрутах внешней сети.
При восстановлении связи происходит объединение, адаптация конфигурации. Это повышает утилизацию CPU на время синхронизации. Возможно перезапуск репликации БД, если резервный инстанс в момент потери связи оказался на выбранном острове и был превращен в мастер. А в ином случае лога транзакций PostgreSQL может хватить для возобновления потоковой репликации после объединения островов.
|
Вывод: Учитывать проблему сплит-брейна нужно обстоятельно в каждом проекте, настраивать кворум, арбитра, а при необходимости и кросс-маршруты через внешнюю сеть с арбитром. А если серверы не в одной подсети, так что могут оказаться одновременно доступными, то со всей серьезностью следует подходить и к настройке внешних доступов между серверами для осуществления выборов. |
Плюсы и минусы двухсерверной конфигурации
Сравниваем двухсерверную конфигурацию с односерверной.
Плюсы
-
Способность к отказоустойчивости: удовлетворяются требования.
-
Повышение надежности через автоматическое восстановление доступности.
-
Возможность сохранения текущих разговоров (*).
-
Готовность архитектуры к ad-hoc масштабированию (добавление серверов без перепроектирования).
-
Доступность плавного вывода сервера из эксплуатации.
-
Отсутствие явной необходимости производить бэкапы данных – всё хранится дважды.
Минусы и требования
-
Значимый объем требований и работ в инфраструктуре.
-
Трансляция требований к смежным системам и устройствам (клиенты тоже должны уметь переключаться, а сервисы должны быть HA).
-
Усложнение работы с диском: необходимость внешнего сетевого файлового хранилища (S3/NFS).
-
Увеличенная idle-нагрузка: данные дублируются в реальном времени, рассылаются хартбиты.
-
Увеличенные тайминги: межсервисные запросы стали на несколько пингов дольше.
-
Необходимость синхронизации времени (NTP).
-
Увеличенная сложность сопровождения: логи распределены, обновление контейнеров сложнее.
-
Риск сплит-брейна и необходимость настройки кворума (арбитр, внешние адреса).
-
Необходимость выноса БД в надсистему или принятие риска длительного отсутствия реплики при использовании встроенных средств.
-
Для сохранения текущих разговоров все равно необходимо добавлять серверы или использовать сервис восстановления разговоров.
Идеальный HA-контур
Давайте соберём всё в единую картину. Перед вами архитектура, к которой стоит стремиться при построении отказоустойчивого решения на платформе «Эра» в двухсерверной конфигурации.
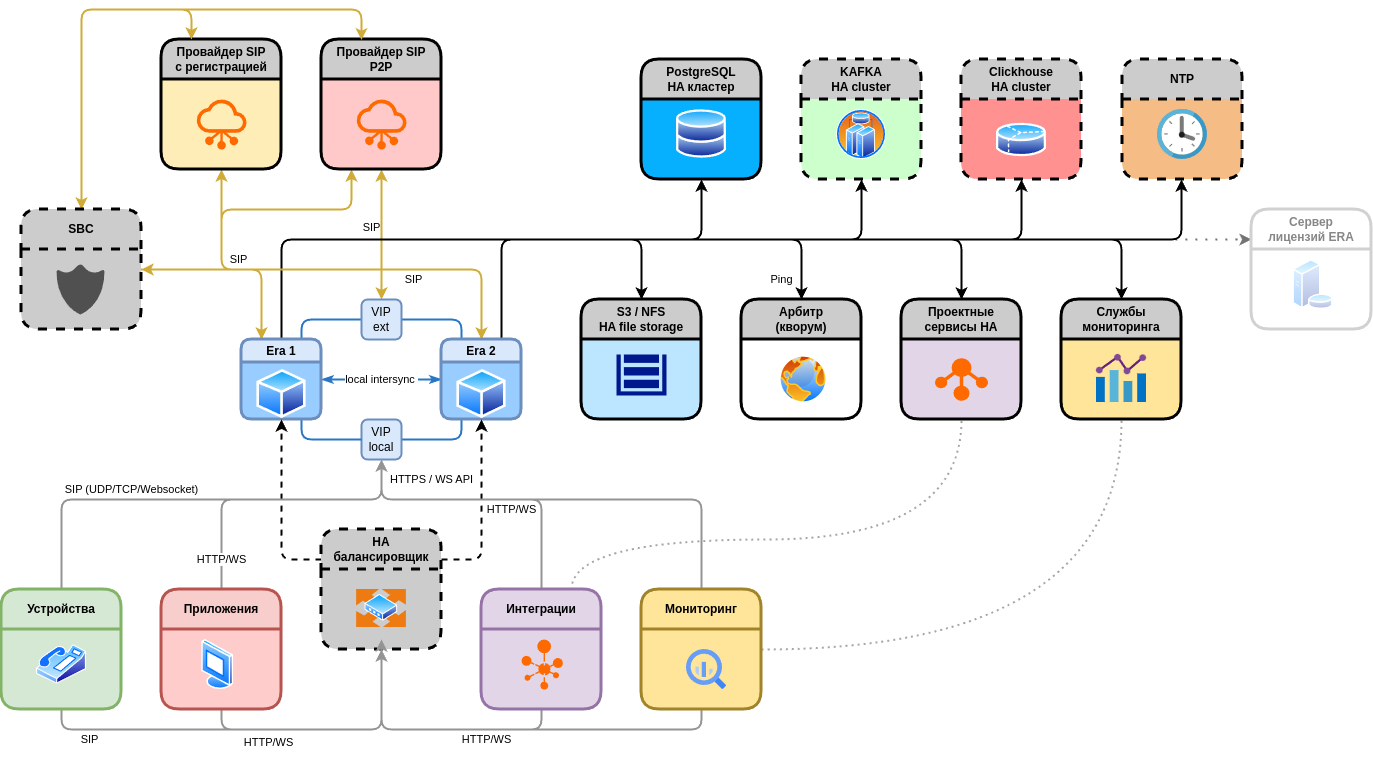
Обратите внимание: платформа — это только часть системы. Внешний кластер баз данных обеспечивает кворум и надежную администрируемую репликацию. S3-хранилище гарантирует доступность файлов независимо от состояния серверов. Арбитр предотвращает сплит-брейн.
Балансировщик здесь показан опционально. Если ваши клиенты и провайдеры умеют работать с несколькими адресами напрямую — балансировщик не нужен. Это избавляет от ещё одного компонента, который нужно резервировать и администрировать. Балансировщик имеет смысл, когда нужно скрыть внутреннюю структуру, обеспечить заданное распределение подключений по узлам или клиенты не поддерживают multi-homing при том, что не используется ни Virtual IP, ни Multi DNS.
| Обязательно настраиваются средства мониторинга и отслеживаются показатели. Определенно лучше упредить негативную ситуацию, чем разбираться с ее последствиями. |
| Платформа позволяет начать с одного сервера, и затем расширить конфигурацию без миграции накопленных данных. |
Ключевой месседж: отказоустойчивость — это не кнопка, а архитектура. Платформа «Эра» даёт инструменты, но успех зависит от грамотного проектирования всей суперсистемы.
Альтернативный подход: Active-Passive с гео-распределением
Кстати говоря, два сервера могут решать задачу резервирования совершенно иным способом — не как равноправные узлы Active-Active, а в режиме Primary-Secondary.
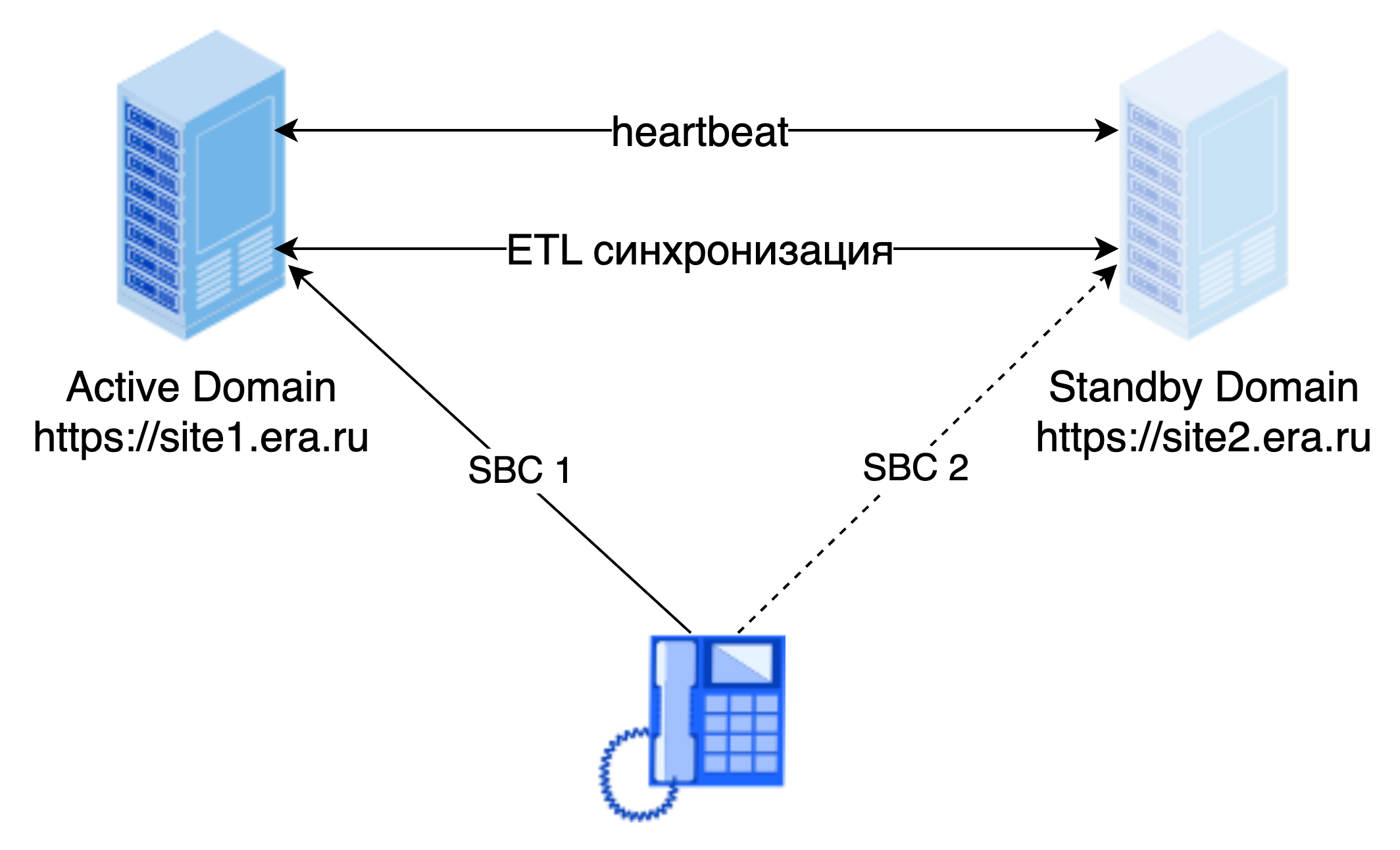
Как это работает
-
Primary (преимущественно активный) — обрабатывает всю нагрузку, собирает исторические данные.
-
Secondary (преимущественно пассивный) — находится в режиме ожидания, может быть вынесен географически.
-
Репликация настроек — настройки домена реплицируются в реальном времени с активного на пассивный.
-
Исторические данные — собираются на Primary; Secondary отправляет свои локальные данные на Primary после восстановления связи и его активации.
Поведение пассивной системы
-
Отключает сервисы, изменяющие данные.
-
На фасадах выставляет перенаправление: обычные пользователи автоматически уходят на Primary, только администратор может подключиться напрямую для обслуживания.
-
Если в течение 30 секунд не чувствует Primary — активируется и начинает обслуживать вызовы.
При восстановлении Primary
-
Не забирает активность автоматически.
-
Работает некоторое время в пассивном режиме.
-
Передача активности обратно происходит по недоступности активного или по сигналу администратора в подходящий технологический интервал.
Особенности подхода
| Особенность | Что это значит |
|---|---|
⚠️ Процессы реального времени не переносятся |
Активные вызовы при переключении обрываются — это компромисс за простоту и скорость активации |
✅ Минимальное время активации |
Пассивная система частично загружена, «прогрета» и готова к работе |
✅ Настройки конфигурации, подключения к внешнему миру |
Индивидуальны и независимы |
Низкая зацепленность двух систем. |
✅ Никакого realtime и инфраструктуры. Переносятся только целевые бизнес-данные длительного хранения и использования с тонкой настройкой фильтров. |
✅ Актуальные настройки домена в реальном времени |
Учетки, правила, сценарии, очереди - всё что необходимо - синхронизируются постоянно с активного на пассивный |
✅ Единый источник исторических данных |
Все архивы собираются на Primary — проще аналитика и отчетность |
✅ Совместимость с распределёнными хранилищами |
Обе системы могут писать в единую Kafka+ClickHouse-инфраструктуру |
✅ Предсказуемая нагрузка |
Нагружена только одна система — проще планировать ресурсы |
✅ Тестирование без риска |
В любой момент можно провести проверку готовности Secondary |
✅ Независимое обслуживание и обновление |
Пока обслуживается или обновляется Primary, работу делает Secondary. Разница версий - не проблема. |
✅ Границы домена |
Режим применяется для резервирования не системы целиком, а конкретного домена. |
Когда этот подход оправдан
-
Требуется гео-резервирование (серверы в разных ЦОД/городах).
-
Нет High Available инфраструктуры, зато есть две независимые площадки.
-
Приемлема потеря активных сессий при переключении.
-
Нужна возможность тестирования готовности резервного узла, в том числе без влияния на продакшн.
-
Упрощённая модель администрирования: одна система активна, вторая — «на подхвате». ETL вместо UnSplit-Brain.
|
Вывод: Active-Passive — это не «упрощённая» версия двухсерверной конфигурации, а осознанный архитектурный выбор со своими компромиссами. Он может быть предпочтительнее Active-Active, когда важнее гео-устойчивость и простота управления, чем возможность сохранения активных сессий. |